The problem
When developing on a web application unintended side effects in the form of visual changesare likely to occur. The manual process for finding these issues is long and tedious and existing tools suffer from either bad recall or bad precision.
The most prevalent technique to define where there is a visual change is referred to as the pixel-by-pixel method and simply consists of comparing the individual pixels of two images. One image is taken before the change and the other image is taken after the code changes are applied. The idea behind this is that if a pixel has changed color, this must bean indicator that either an element has moved, been removed, changed property or state in some way.
This novel approach suffers from 2 issues.
- We don’t know what the issue is and have no means of easily identify it.
- We are highly suceptible for the cascading error problem.
Here is the same test, but with 1 additional change. Header has added 20px padding on the bottom. Now test has too many false positives that to be useful for anything.

The solution concept
As part of my Master thesis a proof-of-concept was developed to demonstrate if the assumption: “Any visual change the enduser can perceive will appear as a change in the HTML or rendered CSS.” was correct.
To detect changes in the DOM it’s easy to find changes when elements are modified. Find the 2 same elements and compare their CSS properties. If there is changes, there should also be a visual change.
The challenge comes when elements (html tags) are added, removed or moves location in the DOM. Here we lose the ability to compare, because if elements are moved and we compare the wrong elements the program will compare the style of the wrong elements.
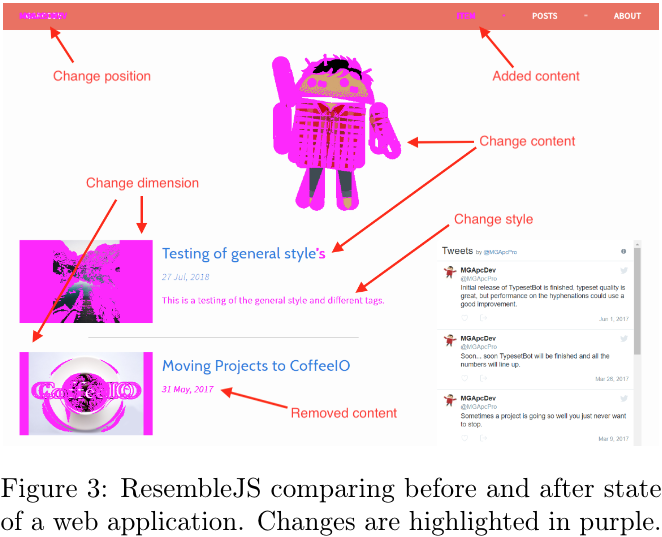
To solve this we use a Tree Edit Distance algorithm that will give the minimum number of changes to transform one tree into another. To do this, the algotihm needs to define with elements are the same, which provides the matching of which elements are the same, added, removed and updated. This project uses Zhang-Shasha to match elements.
The Zhang-Shasha has a performance of n4 (where n is the number of nodes in the DOM tree) which becomes probematic with bigger web applications that can contain thousands of nodes.
For the purpose of VRT we can assume “Most subtrees will remain unchanged, as multiple changes happen within the same subtree”
Due to this assumption we can perform a preprocessing step to remove identical subtrees. This will significantly reduce the size of the DOM tree, which dramatically improves performance of Zhang-Shasha. With subtree matching the reduction in a balances tree can be defined as 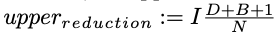 here D represents the max depth in the tree, B is the branching factor, I is the number of changes and N is the number of nodes. An upper bound of 0,3 would mean the tree can be reduced to 30% or less of it’s original size.
here D represents the max depth in the tree, B is the branching factor, I is the number of changes and N is the number of nodes. An upper bound of 0,3 would mean the tree can be reduced to 30% or less of it’s original size.
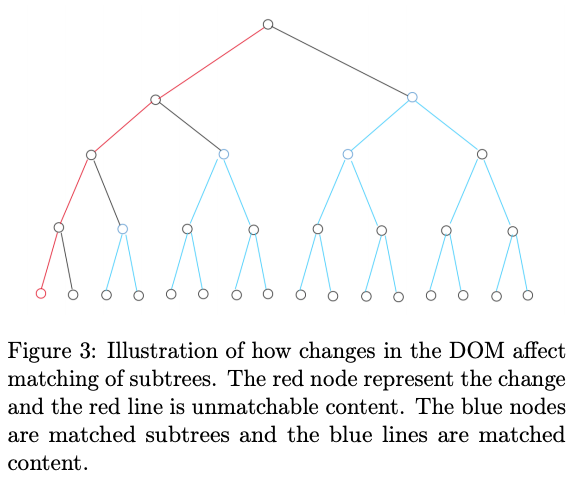
From this we get a pretty good result, but with one major issue. Not all changes in CSS will produce visual changes. Therefore any changes will be run through visual verification, where pixels of the affected area are compared to check if there is any visual difference.
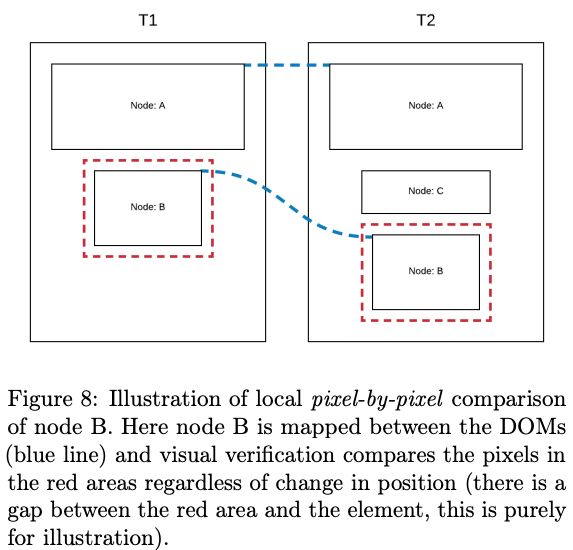
(code and thesis paper is not publically awailable, email for more info mgapcdev@gmail.com)
The results
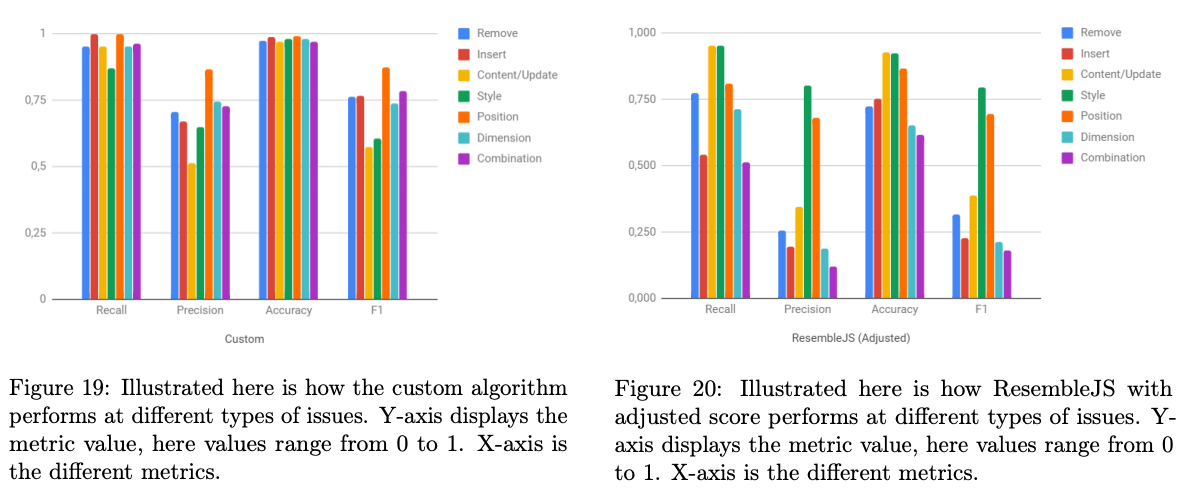
- Here is illustrated how the visual difference detected is visual represented.
- Since all detected differences are on a node level, detailed information of node, location and type of issue can be controlled individually.

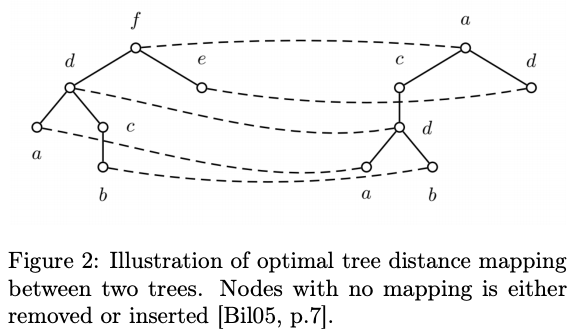
- Here the performance metrics is compared to ResembleJS (pixel-by-pixel comparison). DOM-based VRT outperforms ResembleJS significantly on allmost every metric and change type.